Introduction to the Jax backend#
ReservoirPy v0.4.1 introduces the Jax backend, an implementation of the classical ReservoirPy nodes using the Jax library instead of NumPy. Jax offers several machine learning features, such as differentiation, and allows for Python programs to be executed either on the CPU or on the GPU through function computation, which allows for a significant speed improvement on complex tasks.
An overview of the jax library can be found at https://docs.jax.dev/en/latest/.
[ ]:
%pip install "reservoirpy[jax]"
[2]:
# Imports
import time
import tqdm
import numpy as np
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
rng = np.random.default_rng(seed=260_418)
[3]:
# Depending on your machine, it is sometimes better to only use the CPU
jax.config.update('jax_platform_name', 'cpu')
print(jax.numpy.ones(3).device)
TFRT_CPU_0
Importing Jax nodes#
Jax implementations of classical ReservoirPy classes and methods are mirrored from reservoirpy to reservoirpy.jax:
[4]:
import reservoirpy as rpy
import reservoirpy.jax as rjx
# Data definition
X = rng.uniform(size=(1200, 2))
X_train, X_test = X[:1000], X[1000:]
Y = X @ rng.uniform(size=(2, 1)) + rng.normal(scale=0.1, size=(1200, 1)) # noisy linear combination of X
Y_train, Y_test = Y[:1000], Y[1000:]
[5]:
numpy_model = rpy.nodes.Reservoir(100, lr=0.7) >> rjx.nodes.Ridge(1e-2)
y_pred_np = numpy_model.fit(X_train, Y_train, warmup=10).run(X_test)
jax_model = rjx.nodes.Reservoir(100, lr=0.7) >> rjx.nodes.Ridge(1e-2)
y_pred_jax = jax_model.fit(X_train, Y_train, warmup=10).run(X_test)
Or, with the ESN model:
[6]:
numpy_model = rpy.ESN(units=100, lr=0.7, ridge=1e-2)
jax_model = rjx.ESN(units=100, lr=0.7, ridge=1e-2)
Models with feedback work the same:
[7]:
reservoir, readout = rjx.nodes.Reservoir(100), rjx.nodes.Ridge()
fb_model = (reservoir >> readout) & (reservoir << readout)
_ = fb_model.fit(X_train, Y_train, warmup=10).run(X_test)
As well as big models with complex interactions (as shown in the Advanced Features guide):
[8]:
reservoir1 = rjx.nodes.Reservoir(100, name="res1-3")
reservoir2 = rjx.nodes.Reservoir(100, name="res2-3")
reservoir3 = rjx.nodes.Reservoir(100, name="res3-3")
readout1 = rjx.nodes.Ridge(name="readout2")
readout2 = rjx.nodes.Ridge(name="readout1")
model = [reservoir1, reservoir2] >> readout1 & \
[reservoir2, reservoir3] >> readout2
Note that the ScikitLearnNode interface does not have a Jax implementation, since scikit-learn only has a NumPy backend. But you can seamlessly compose Jax nodes with NumPy nodes:
[ ]:
from sklearn.linear_model import RidgeCV
reservoir = rjx.nodes.Reservoir(100)
readout = rpy.nodes.ScikitLearnNode(RidgeCV)
model = reservoir >> readout # Reservoir in jax, RidgeCV in numpy + scikit-learn
Moreover, nodes and models from the ReservoirPy-Jax backend interoperate nicely with all ReservoirPy modules (hyper, observables, …)
Performances#
Thanks to Jax code compilation and optimization, and its ability to run on GPUs, you can expect a significant performance boost on large models and with large datasets, making it ideal of resource intensive tasks.
Here, we are illustrating this on ESN with reservoirs of various size, processing a timeseries of 100.000 timesteps, both using numpy and jax.
[9]:
N_NEURONS_LIST = np.logspace(1, 4, 7, dtype=np.int64)
X = rng.uniform(size=(50_000, 1))
numpy_scores = np.zeros(len(N_NEURONS_LIST))
jax_scores = np.zeros(len(N_NEURONS_LIST))
print("Running on device: ", jax.numpy.ones(1).device)
for i, n_neuron in enumerate(N_NEURONS_LIST):
print(f"{n_neuron} neurons:")
params = dict(
units=n_neuron,
rc_connectivity=5/n_neuron,
input_connectivity=5/n_neuron,
ridge=10,
)
model = rpy.ESN(**params)
start = time.time()
model.fit(X, X).run(X)
stop = time.time()
numpy_scores[i] = stop - start
print(f"\tNumPy time: {numpy_scores[i]:.3}s", end="")
model = rjx.ESN(**params)
start = time.time()
model.fit(X, X).run(X)
stop = time.time()
jax_scores[i] = stop - start
print(f"\tJax time: {jax_scores[i]:.3}s")
plt.figure()
plt.title("Running time on 50K timesteps")
plt.plot(N_NEURONS_LIST, numpy_scores, "-+", color="#4d77cf", label="NumPy backend")
plt.plot(N_NEURONS_LIST, jax_scores, "-+", color="#9c27b0", label="JAX backend")
plt.xscale("log")
plt.xlabel("Number of neurons in the reservoir")
plt.xticks(N_NEURONS_LIST, N_NEURONS_LIST)
plt.ylabel("Execution time (s)")
plt.legend()
plt.grid()
plt.show()
Running on device: TFRT_CPU_0
10 neurons:
NumPy time: 1.06s Jax time: 0.953s
31 neurons:
NumPy time: 1.1s Jax time: 0.892s
100 neurons:
NumPy time: 1.24s Jax time: 0.538s
316 neurons:
NumPy time: 1.83s Jax time: 1.07s
1000 neurons:
NumPy time: 3.57s Jax time: 1.72s
3162 neurons:
NumPy time: 10.6s Jax time: 4.21s
10000 neurons:
NumPy time: 1.21e+02s Jax time: 20.0s
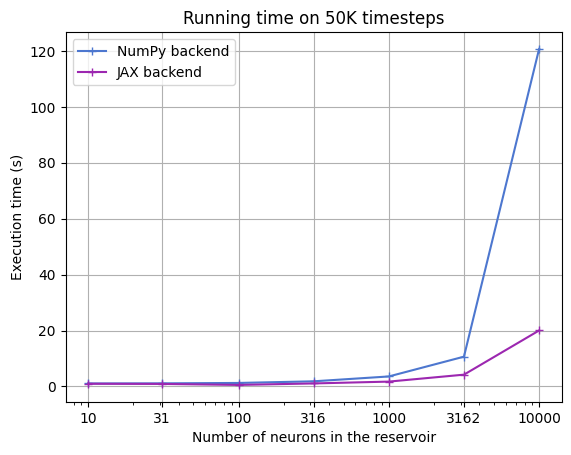
We can see a major improvement in execution time between the numpy and the jax models. This will be dependent on your task, model, and of course your hardware.
Differentiation of ReservoirPy nodes and models#
With the Jax backend of ReservoirPy, you can now compute the gradient of any pure-jax nodes or models.
Jacobian of a Node#
Let’s compute the jacobian of the edge of stability reservoir:
[10]:
# create a simple ES2N jax node
node = rjx.nodes.ES2N(5, proximity=0.7, sr=0.3, input_connectivity=0.5)
# warm it up
X = rng.uniform(0, 1, (200, 2))
_ = node.run(X)
Every node have their _step method. This is a pure function, that takes two arguments:
The previous node state: this represents the state of the node as a dict of 1-D arrays. Its
"out"key holds the previous output of the node.The input. This is a 1-D array (a timestep).
This method returns a dict that represents the new state of the node. The "out" key holds the output of the node.
Knowing this, we can now compute the gradient out of the input or the previous node state.
[11]:
# observation point
x = rng.uniform(0, 1, (2,))
# Jacobian of ES2N with respect to the previous ES2N neurons state
jac_from_state = jax.jacobian(node._step, argnums=0)(node.state, x)["out"]["out"]
# Jacobian of ES2N with respect to the input
jac_from_input = jax.jacobian(node._step, argnums=1)(node.state, x)["out"]
print("Jacobian from the previous node state")
print(jac_from_state, jac_from_state.shape)
print()
print("Jacobian from the input")
print(jac_from_input, jac_from_input.shape)
Jacobian from the previous node state
[[ 0.39231694 0.01568126 -0.23276064 -0.04635323 0.00888896]
[-0.10896099 0.13722752 -0.04822905 -0.17233549 -0.165138 ]
[ 0.08274485 -0.09067826 0.0278561 0.10745058 -0.25021824]
[ 0.12227463 -0.11532653 0.13048898 -0.21138966 0.00597949]
[-0.15159406 -0.22226101 -0.12527217 -0.04382525 -0.00235007]] (5, 5)
Jacobian from the input
[[ 0. 0. ]
[ 0.3467805 0.3467805]
[ 0. 0. ]
[ 0. -0.6393939]
[ 0. 0. ]] (5, 2)
Jacobian of a Model#
The jacobian of a Model follows the same logic, though it is a bit more complex since we are handling more states and outputs at the same time.
Let’s create a simple echo state network.
[12]:
reservoir = rjx.nodes.Reservoir(10)
readout = rjx.nodes.Ridge(1e-3)
model = reservoir >> readout
Y = rng.uniform(0, 1, (200, 1))
model.fit(X, Y)
[12]:
Model(Reservoir(units=10, input_dim=2), Ridge(ridge=0.001, input_dim=10, output_dim=1))
Model also have their _step purely-functional method. It takes two arguments:
The previous model state: this is a tuple where the first element is a mapping of the feedback buffers (we don’t have any here), and a mapping of the node states.
The input. This is a mapping of 1-D arrays (timesteps).
This method returns a dict that represents the new state of the model as described above.
[13]:
# Illustration of the _step method
new_buffers, new_states = model._step(
(model.feedback_buffers, {n: n.state for n in model.nodes}),
{reservoir: x}
)
new_states
[13]:
{Ridge(ridge=0.001, input_dim=10, output_dim=1): {'out': Array([0.4705091], dtype=float32)},
Reservoir(units=10, input_dim=2): {'out': Array([-0.3220906 , 0.04102203, -0.01304624, 0. , 0. ,
0. , 0.23301846, 0. , 0.29908204, 0. ], dtype=float32)}}
Now that we have this in mind, we can compute its jacobian!
[14]:
# Jacobian of ESN model with respect to the input
jac_from_input = jax.jacobian(model._step, argnums=1)(
(model.feedback_buffers, {n: n.state for n in model.nodes}),
{reservoir: x}
)
# output of the readout with respect to the input
# we want to get the jacobian of the [1][readout]["out"] output relative to the [reservoir] input
jac_from_input[1][readout]["out"][reservoir]
[14]:
Array([[-0.1528503, -0.0186974]], dtype=float32)